Pandas 是
Python界最流行的数据统计基础库之一。但像我这样和Java/Scala打交道的人,还是期望JVM有类似的解决方案。网上一搜发现生态还是很丰富的:大数据领域的 Spark ,支持 GUI 的数据挖掘套件 weka ,主攻机器学习的 smile ,擅长聚合变换的 joinery 等等。但小虫最终还是选择了简约而不简单的 tablesaw 。缘由还得从那句老话说起: 离开场景谈应用都是耍流氓 。
应用场景
数据:处理流程
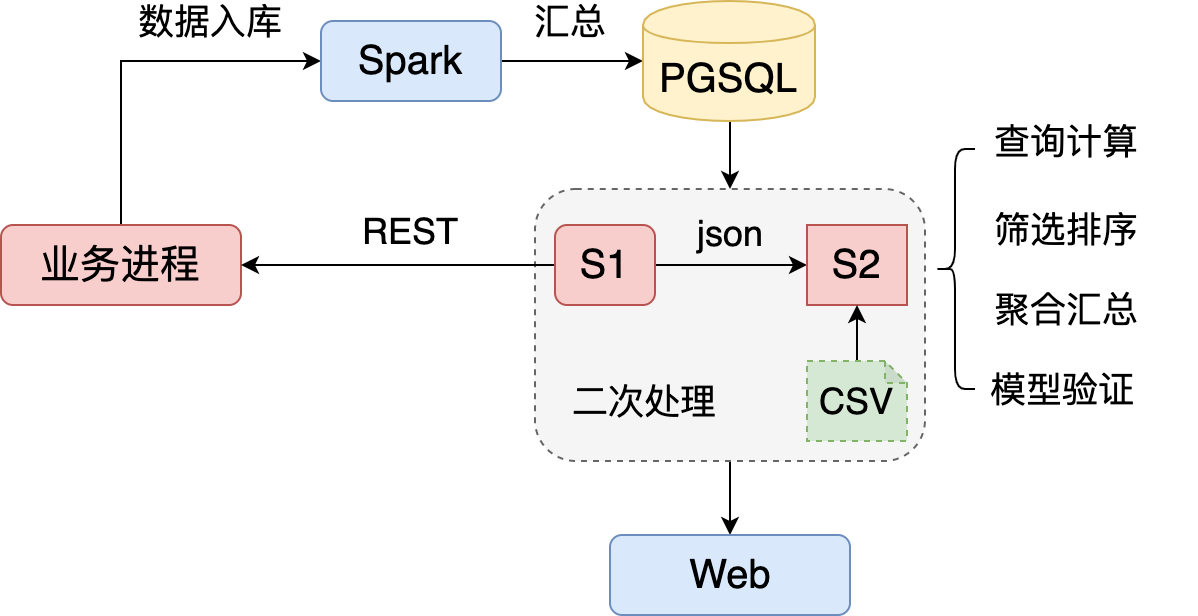
Spark 将业务产生的海量用户行为按模块加工:过滤冗余/简单汇总,并导出至 PostgreSQL 的不同表中,存储正交化的基础数据。比如用户的登陆/购买行为分别记录到, LoginTable 和 ShoppingTable 。然后在 二次处理 模块中建立不同服务,比如 S1,S2。S1 直接访问数据库,S2 的既要访问数据库,又要访问 S1 的统计结果,还要依赖本地的 csv 文件。
计算需求分类
-
查询计算。整表查询,列的统计,变换等。
-
筛选排序。条件查询,自定义多重排序等。
-
聚合连接。比如
LoginTable记录终端类型:android/iOS;ShoppingTable记录了用户购买物品的种类和数量。当要对比不同终端用户购买行为差异时,就要将两个表连接并按终端类型聚合。 -
模型验证。评估决策需要的分析模型多变,要经过反复调整得到最终结果。关键在于 快速迭代 。
特点汇总
| 纬度 | 特点 | 说明 |
|---|---|---|
| 数据量 | 较小单机可承载 | 原始数据由 spark 汇总 |
| 格式 | 数据库,本地 csv,json | json 多来自于 restful 服务 |
| 计算 | 增删改查,条件查询,表连接,聚合,统计 | 内置算子越多,扩展性越高越好 |
| 交互 | 输出到指定格式,可视化,可交互 等 | 网页渲染,终端,Jupyter Notebook |
| 集成 | 轻量,以库而非服务的形式 | 便于嵌入进程和其他逻辑交互 |
为何选择 tablesaw
很简单,就因为它完美契合小虫的应用场景。借用 tablesaw官网 的特性列表:
-
数据导入:RDBMS,Excel,CSV,Json,HTML 或固定宽度文件。除了支持本地访问,还支持通过 http,S3 等远程访问。
-
数据导出:CSV,Json,HTML 或固定宽度文件。
-
表格操作:类似
Pandas DataFrame,增删改查,连接,排序。
以上是基础功能,小虫觉得下面几个点更有意思:
-
基于Plotly 的可视化框架。摆脱
java的 UI 系统,更好的和 Web 对接。支持 2D、3D 视图,图表类型也很丰富:曲线,散点,箱形统计,蜡烛图,热力图,饼状图等。更重要的是:-
交互式图表。特别适合多种数据集对比,以及三维视角旋转。
-
图表导出为字符串形式
Javascript。方便结合 Web Service 渲染 html。
-
-
与
smile对接。tablesaw 可将表格导出为smile识别的数据格式,便于利用其强大的机器学习库。
好了,说了这么多,直接上干货吧。
基本应用
安装
tablesaw 包含多个库,小虫推荐安装 tablesaw-core 和 tablesaw-jsplot 。前者是基础库,后者用于渲染图表。其它如 tablesaw-html, tablesaw-json, tablesaw-breakerx 主要是对数据格式变化的支持,可按需选择。其实结合需求写两行代码就行,轻量又灵活。以 tablesaw-core 为例说明 Jar 包安装方法:
|
|
|
|
表格创建
两种基本方式:
-
从数据源读取直接创建
-
创建空表格编码增加列或行
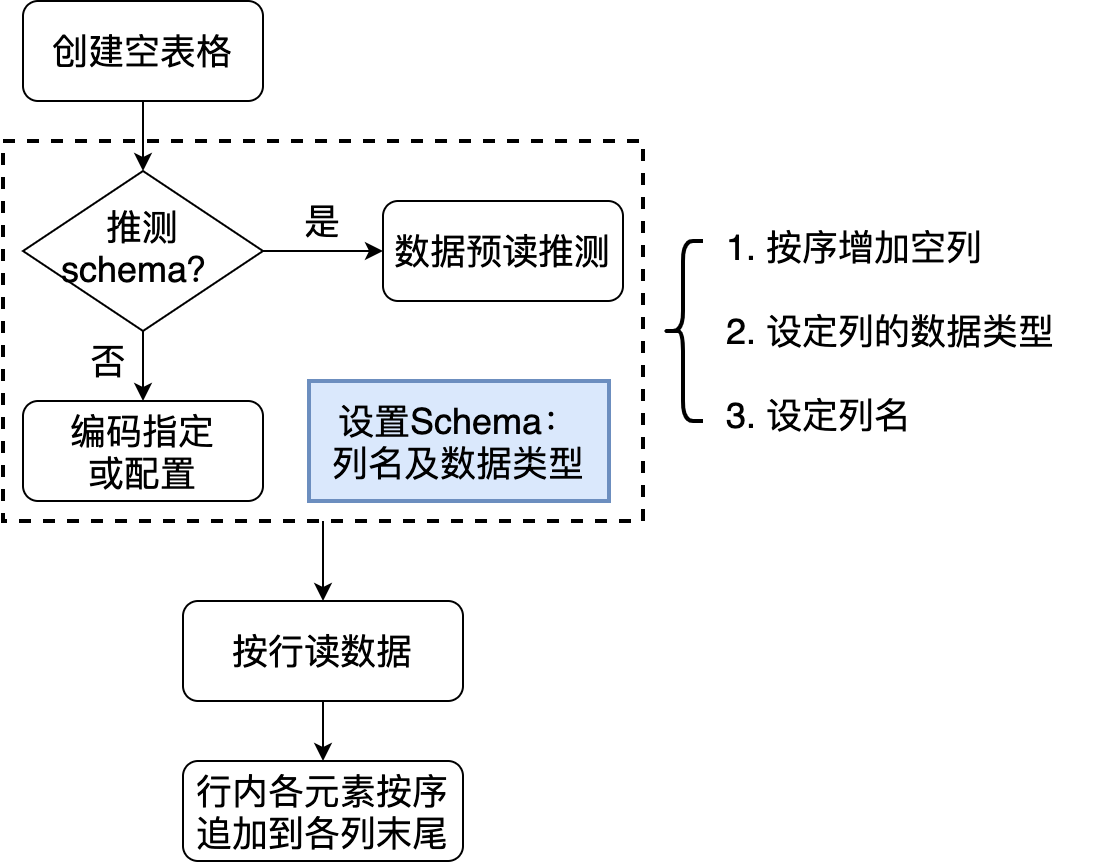
下面先定义需要处理的 csv 文件格式。第一列为日期,第二列为姓名,第三列为工时(当日工作时长,单位是小时),第四列为报酬(单位是元)。然后举三个典型例子来说明导入的不同方式。
1. CSV 直接导入
|
|
| date | name | 工时 | 报酬 |
|---|---|---|---|
| 2019-01-08 | tom | 8 | 1000 |
| 2019-01-09 | jerry | 7 | 500 |
| 2019-01-10 | 张三 | 8 | 999 |
| 2019-01-10 | jerry | 8 | 550 |
| 2019-01-10 | tom | 8 | 1000 |
| 2019-01-11 | 张三 | 6 | 800 |
| 2019-01-11 | 李四 | 12 | 1500 |
| 2019-01-11 | 王五 | 8 | 900 |
| 2019-01-11 | tom | 6.5 | 800 |
可以发现能够比较完美的推测,并对中文支持良好。输出 schema 为:
String column: name
Double column: 工时
Integer column: 报酬
tablesaw 目前支持的数据类型有以下几种:SHORT, INTEGER, LONG ,FLOAT ,BOOLEAN ,STRING ,DOUBLE ,LOCAL_DATE ,LOCAL_TIME ,LOCAL_DATE_TIME ,INSTANT, TEXT, SKIP。绝大部分列和普通数据表类型没有差异,为一需要强调的是:
-
INSTANT。可以精确到纳秒的时间戳,自 Java 8 引入。
-
SKIP。指定列忽略不读入。
2. 指定 schema 从 CSV 导入
有时自动推测并不会非常精准,比如期望使用 LONG ,但识别为 INTEGER ;或在读入后追加数据时类型会有变化,比如报酬读入是整型但随后动态增加会有浮点数据。这时就需要预先设定 csv 的 schema ,这时可以利用 tablesaw 提供的 CsvReadOptions 实现。比如预先设置报酬为浮点:
|
|
输出 schema 为:
String column: name
Double column: 工时
Double column: 报酬
3. 编码设定 schema 和数据填充
该方法适合各种场景,可以运行时从不同数据源导入数据。
基本流程是:
- 创建空表格,同时设定名称
- 设定 schema:向表格中按序增加指定了 =名称= 和 =数据类型= 的列。
- 向表格中按行追加数据。每行中的元素分别添加到指定列中。
|
|
创建一个函数将获取的数据集合添加到表格中:
|
|
上面的说明了数据添加的完整过程:创建表格,增加列,列中追加元素。基于这三个基本操作基本可以实现所有的创建和形变。
列处理
列操作是表格处理的基础。前面介绍了列的数据类型,名称设置和元素追加,下面继续介绍几个基础操作。
1. 遍历与形变
比如按序输出 demo 表格中所有记录的姓名:
|
|
除了遍历外,另一种常见应用是将列形变到另外一列:类型不变值变化;类型变化。以工时为例,我们将工时不小于 8 则视为全勤:
|
|
| date | name | 工时 | 报酬 | 全勤 |
|---|---|---|---|---|
| 2019-01-08 | tom | 8 | 1000 | true |
| 2019-01-09 | jerry | 7 | 500 | false |
| 2019-01-10 | 张三 | 8 | 999 | true |
| 2019-01-10 | jerry | 8 | 550 | true |
| 2019-01-10 | tom | 8 | 1000 | true |
| 2019-01-11 | 张三 | 6 | 800 | false |
| 2019-01-11 | 李四 | 12 | 1500 | true |
| 2019-01-11 | 王五 | 8 | 900 | true |
| 2019-01-11 | tom | 6.5 | 800 | false |
2. 列运算
tablesaw 提供了丰富的针对列的运算函数,而且针对不同数据类型提供了不同特化接口。建议优先查阅 API 文档,最后考虑写代码。这里介绍几个大类:
-
多列交叉运算。比如一列中所有元素和同一数据计算,或者两列元素按序交叉计算。比如每人的时薪:
|
|
-
单列的统计。均值,标准差,最大 N 个值,最小 N 个值,窗口函数等。
|
|
-
排序。数值,时间,字符串类型默认支持增序、降序,也支持自定义排序。
3. 过滤
tablesaw 对列的过滤条件定义为 Selection ,不同的条件可以按“与、或、非”组合。每种类型的列均提供 "is" 作为前缀的接口直接生成条件。下面举个例子,找到工作时间在 2019-01-09 - 2019-01-10 之间工时等于 8 且报酬小于 1000 的所有记录:
|
|
| date | name | 工时 | 报酬 | 全勤 |
|---|---|---|---|---|
| 2019-01-10 | 张三 | 8 | 999 | true |
| 2019-01-10 | jerry | 8 | 550 | true |
表格处理
除了基础操作可以参考官网说明外,有三种表格的操作特别值得一提:连接,分组聚合,分表。
连接
将有公共列名的两个表连接起来,基本方式是以公共列为 key,将各表同行其它列数据拼接起来生成新表。根据方式的不同组合有所差异:
-
inner. 公共列中的数据取交集,其他过滤。
-
outer. 公共列中的数据取并集,缺失的数据设置默认空值。具体又可以分为三类:
-
leftOuter. 结果表公共列数据与左侧表完全相同,不在其中的过滤,缺失的设置空值。
-
rightOuter. 结果表公共列数据与右侧表完全相同,不在其中的过滤,缺失的设置空值。
-
fullOuter. 结果表公共列数据为两个表的并集,缺失的设置空值。
-
举个例子,增加一个新表 tbl2 记录每人的工作地点:
| name | 地点 |
|---|---|
| 张三 | 总部 |
| 李四 | 门店 1 |
| 王五 | 门店 2 |
采用 inner 方式和 demo 表连接:
|
|
| date | name | 工时 | 报酬 | 全勤 | 地点 |
|---|---|---|---|---|---|
| 2019-01-10 | 张三 | 8 | 999 | true | 总部 |
| 2019-01-11 | 张三 | 6 | 800 | false | 总部 |
| 2019-01-11 | 李四 | 12 | 1500 | true | 门店 1 |
| 2019-01-11 | 王五 | 8 | 900 | true | 门店 2 |
可以发现,按照 name 的交集连接,tom 和 jerry 都被过滤掉了。
分组聚合
类似于 SQL 中的 groupby,接口为: tbl.summarize(col1, col2, col3, aggFunc1, aggFunc2 ...).by(groupCol1, groupCol2) 。其中 by 的参数表示分组列名集合。summarize 的 col1, col2, col3 表示分组后需要被聚合处理的列名集合, aggFunc1, aggFunc2 表示聚合函数,会被用于所有的聚合列。举个例子计算每人的总报酬:
|
|
| name | Sum [报酬] |
|---|---|
| tom | 2800 |
| jerry | 1050 |
| 张三 | 1799 |
| 李四 | 1500 |
| 王五 | 900 |
分表
和分组聚合不同,按列分组后,可能并不需要将同组数据聚合为一个值,而是要保存下来做更加复杂的操作,这时就需要分表。接口很简单: tbl.splitOn(col ...) 设定分表的列名集合。比如:
|
|
可视化
tablesaw 可以将表格导出为交互式 html,也支持调试时直接调研调用浏览器打开,并针对不同类型图表做了个性化封装。举个简单例子,查看每人报酬的时间变化曲线:
|
|
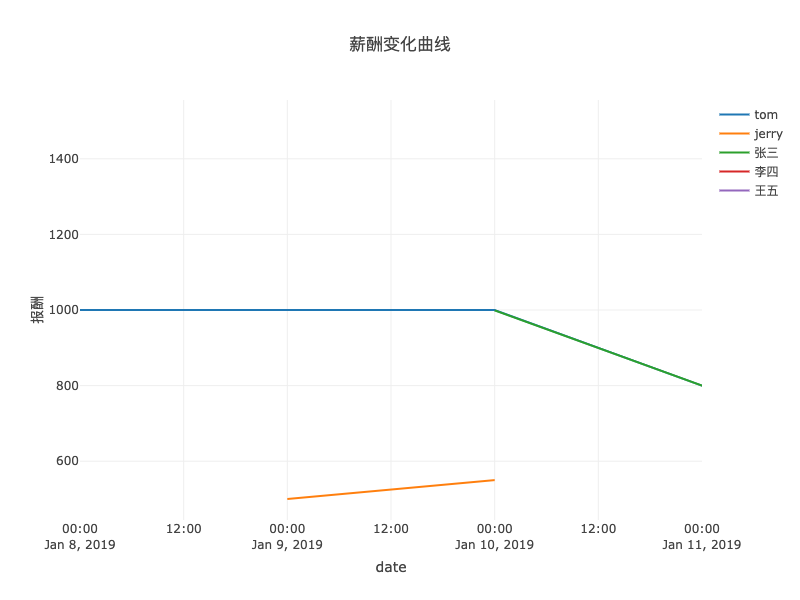
小结
小虫向大家简单介绍了 tablesaw 的功能和使用方法,从我自己的使用经验而言,我最喜欢它的的地方在于:
-
api 接口的统一,清晰
-
交互式图表生成简单,能够和 web 对接
此外, tablesaw 的开发和维护也如火如荼,期待后续有更多的有趣的功能添加进来。
